评估
“Evals” 指的是评估一个模型在特定应用中的性能。
警告
与单元测试不同,评估是一门新兴的艺术/科学;任何声称确切知道应如何定义您的评估的人都可以被安全地忽略。
Pydantic Evals 是一个强大的评估框架,旨在帮助您系统地测试和评估所构建系统的性能和准确性,尤其是在使用大语言模型(LLM)时。
我们将 Pydantic Evals 设计得既实用又不过于固执己见,因为我们(和其他所有人一样)仍在探索最佳实践。我们非常期待您对该软件包以及如何改进它的反馈。
Beta 测试版
Pydantic Evals 的支持是在 v0.0.47 中引入的,目前处于 beta 测试阶段。API 可能会发生变化,文档也不完整。
安装
要安装 Pydantic Evals 包,请运行
pip install pydantic-evals
uv add pydantic-evals
pydantic-evals 不依赖于 pydantic-ai,但如果您想在评估中使用 OpenTelemetry 追踪,或将评估结果发送到 logfire,它有一个可选的 logfire 依赖。
pip install 'pydantic-evals[logfire]'
uv add 'pydantic-evals[logfire]'
数据集与测试用例
在 Pydantic Evals 中,一切都始于 Dataset(数据集)和 Case(测试用例)
from pydantic_evals import Case, Dataset
case1 = Case(
name='simple_case',
inputs='What is the capital of France?',
expected_output='Paris',
metadata={'difficulty': 'easy'},
)
dataset = Dataset(cases=[case1])
(这个例子是完整的,可以“按原样”运行)
评估器
评估器是分析和评分您的任务在针对某个测试用例进行测试时结果的组件。
Pydantic Evals 包含几个内置评估器,并允许您创建自定义评估器。
from dataclasses import dataclass
from pydantic_evals.evaluators import Evaluator, EvaluatorContext
from pydantic_evals.evaluators.common import IsInstance
from simple_eval_dataset import dataset
dataset.add_evaluator(IsInstance(type_name='str')) # (1)!
@dataclass
class MyEvaluator(Evaluator):
async def evaluate(self, ctx: EvaluatorContext[str, str]) -> float: # (2)!
if ctx.output == ctx.expected_output:
return 1.0
elif (
isinstance(ctx.output, str)
and ctx.expected_output.lower() in ctx.output.lower()
):
return 0.8
else:
return 0.0
dataset.add_evaluator(MyEvaluator())
- 您可以使用
add_evaluator方法向数据集中添加内置评估器。 - 这个自定义评估器根据输出是否与预期输出匹配返回一个简单的分数。
(这个例子是完整的,可以“按原样”运行)
评估过程
评估过程涉及针对数据集中的所有测试用例运行一个任务。
将上述两个示例结合起来,并使用更具声明性的 evaluators 关键字参数来创建 Dataset
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import Evaluator, EvaluatorContext, IsInstance
case1 = Case( # (1)!
name='simple_case',
inputs='What is the capital of France?',
expected_output='Paris',
metadata={'difficulty': 'easy'},
)
class MyEvaluator(Evaluator[str, str]):
def evaluate(self, ctx: EvaluatorContext[str, str]) -> float:
if ctx.output == ctx.expected_output:
return 1.0
elif (
isinstance(ctx.output, str)
and ctx.expected_output.lower() in ctx.output.lower()
):
return 0.8
else:
return 0.0
dataset = Dataset(
cases=[case1],
evaluators=[IsInstance(type_name='str'), MyEvaluator()], # (3)!
)
async def guess_city(question: str) -> str: # (4)!
return 'Paris'
report = dataset.evaluate_sync(guess_city) # (5)!
report.print(include_input=True, include_output=True, include_durations=False) # (6)!
"""
Evaluation Summary: guess_city
┏━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
┃ Case ID ┃ Inputs ┃ Outputs ┃ Scores ┃ Assertions ┃
┡━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
│ simple_case │ What is the capital of France? │ Paris │ MyEvaluator: 1.00 │ ✔ │
├─────────────┼────────────────────────────────┼─────────┼───────────────────┼────────────┤
│ Averages │ │ │ MyEvaluator: 1.00 │ 100.0% ✔ │
└─────────────┴────────────────────────────────┴─────────┴───────────────────┴────────────┘
"""
- 如上所述,创建一个测试用例
- 也如上所述,创建一个自定义评估器函数
- 创建一个包含测试用例的
Dataset,同时在创建数据集时设置evaluators - 我们待评估的函数。
- 使用
evaluate_sync运行评估,它会针对数据集中的所有测试用例运行该函数,并返回一个EvaluationReport对象。 - 使用
print打印报告,其中显示了评估结果,包括输入和输出。我们在此省略了持续时间,只是为了保持打印输出在每次运行时不变。
(这个例子是完整的,可以“按原样”运行)
使用 LLMJudge 进行评估
在此示例中,我们评估一个根据客户订单生成食谱的方法。
from __future__ import annotations
from typing import Any
from pydantic import BaseModel
from pydantic_ai import Agent, format_as_xml
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import IsInstance, LLMJudge
class CustomerOrder(BaseModel): # (1)!
dish_name: str
dietary_restriction: str | None = None
class Recipe(BaseModel):
ingredients: list[str]
steps: list[str]
recipe_agent = Agent(
'groq:llama-3.3-70b-versatile',
output_type=Recipe,
system_prompt=(
'Generate a recipe to cook the dish that meets the dietary restrictions.'
),
)
async def transform_recipe(customer_order: CustomerOrder) -> Recipe: # (2)!
r = await recipe_agent.run(format_as_xml(customer_order))
return r.output
recipe_dataset = Dataset[CustomerOrder, Recipe, Any]( # (3)!
cases=[
Case(
name='vegetarian_recipe',
inputs=CustomerOrder(
dish_name='Spaghetti Bolognese', dietary_restriction='vegetarian'
),
expected_output=None, # (4)
metadata={'focus': 'vegetarian'},
evaluators=(
LLMJudge( # (5)!
rubric='Recipe should not contain meat or animal products',
),
),
),
Case(
name='gluten_free_recipe',
inputs=CustomerOrder(
dish_name='Chocolate Cake', dietary_restriction='gluten-free'
),
expected_output=None,
metadata={'focus': 'gluten-free'},
# Case-specific evaluator with a focused rubric
evaluators=(
LLMJudge(
rubric='Recipe should not contain gluten or wheat products',
),
),
),
],
evaluators=[ # (6)!
IsInstance(type_name='Recipe'),
LLMJudge(
rubric='Recipe should have clear steps and relevant ingredients',
include_input=True,
model='anthropic:claude-3-7-sonnet-latest', # (7)!
),
],
)
report = recipe_dataset.evaluate_sync(transform_recipe)
print(report)
"""
Evaluation Summary: transform_recipe
┏━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━┓
┃ Case ID ┃ Assertions ┃ Duration ┃
┡━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━┩
│ vegetarian_recipe │ ✔✔✔ │ 10ms │
├────────────────────┼────────────┼──────────┤
│ gluten_free_recipe │ ✔✔✔ │ 10ms │
├────────────────────┼────────────┼──────────┤
│ Averages │ 100.0% ✔ │ 10ms │
└────────────────────┴────────────┴──────────┘
"""
- 为我们的任务定义模型 —— 食谱生成任务的输入和任务的输出。
- 定义我们的食谱生成函数 —— 这是我们想要评估的任务。
- 创建一个包含不同测试用例和不同评估标准的数据集。
- 没有预期输出,我们将让大语言模型来评判质量。
- 使用
LLMJudge的针对特定测试用例的评估器,具有一个重点明确的评估标准。 - 适用于所有测试用例的数据集级别评估器,包括一个针对所有食谱的通用质量评估标准。
- 默认情况下,
LLMJudge使用openai:gpt-4o,这里我们使用一个特定的 Anthropic 模型。
(这个例子是完整的,可以“按原样”运行)
保存和加载数据集
数据集可以保存到 YAML 或 JSON 文件,也可以从这些文件中加载。
from pathlib import Path
from judge_recipes import CustomerOrder, Recipe, recipe_dataset
from pydantic_evals import Dataset
recipe_transforms_file = Path('recipe_transform_tests.yaml')
recipe_dataset.to_file(recipe_transforms_file) # (1)!
print(recipe_transforms_file.read_text())
"""
# yaml-language-server: $schema=recipe_transform_tests_schema.json
cases:
- name: vegetarian_recipe
inputs:
dish_name: Spaghetti Bolognese
dietary_restriction: vegetarian
metadata:
focus: vegetarian
evaluators:
- LLMJudge: Recipe should not contain meat or animal products
- name: gluten_free_recipe
inputs:
dish_name: Chocolate Cake
dietary_restriction: gluten-free
metadata:
focus: gluten-free
evaluators:
- LLMJudge: Recipe should not contain gluten or wheat products
evaluators:
- IsInstance: Recipe
- LLMJudge:
rubric: Recipe should have clear steps and relevant ingredients
model: anthropic:claude-3-7-sonnet-latest
include_input: true
"""
# Load dataset from file
loaded_dataset = Dataset[CustomerOrder, Recipe, dict].from_file(recipe_transforms_file)
print(f'Loaded dataset with {len(loaded_dataset.cases)} cases')
#> Loaded dataset with 2 cases
(这个例子是完整的,可以“按原样”运行)
并行评估
您可以在评估期间控制并发性(这可能有助于防止超出速率限制)。
import asyncio
import time
from pydantic_evals import Case, Dataset
# Create a dataset with multiple test cases
dataset = Dataset(
cases=[
Case(
name=f'case_{i}',
inputs=i,
expected_output=i * 2,
)
for i in range(5)
]
)
async def double_number(input_value: int) -> int:
"""Function that simulates work by sleeping for a tenth of a second before returning double the input."""
await asyncio.sleep(0.1) # Simulate work
return input_value * 2
# Run evaluation with unlimited concurrency
t0 = time.time()
report_default = dataset.evaluate_sync(double_number)
print(f'Evaluation took less than 0.5s: {time.time() - t0 < 0.5}')
#> Evaluation took less than 0.5s: True
report_default.print(include_input=True, include_output=True, include_durations=False) # (1)!
"""
Evaluation Summary:
double_number
┏━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━┓
┃ Case ID ┃ Inputs ┃ Outputs ┃
┡━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━┩
│ case_0 │ 0 │ 0 │
├──────────┼────────┼─────────┤
│ case_1 │ 1 │ 2 │
├──────────┼────────┼─────────┤
│ case_2 │ 2 │ 4 │
├──────────┼────────┼─────────┤
│ case_3 │ 3 │ 6 │
├──────────┼────────┼─────────┤
│ case_4 │ 4 │ 8 │
├──────────┼────────┼─────────┤
│ Averages │ │ │
└──────────┴────────┴─────────┘
"""
# Run evaluation with limited concurrency
t0 = time.time()
report_limited = dataset.evaluate_sync(double_number, max_concurrency=1)
print(f'Evaluation took more than 0.5s: {time.time() - t0 > 0.5}')
#> Evaluation took more than 0.5s: True
report_limited.print(include_input=True, include_output=True, include_durations=False) # (2)!
"""
Evaluation Summary:
double_number
┏━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━━┓
┃ Case ID ┃ Inputs ┃ Outputs ┃
┡━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━━┩
│ case_0 │ 0 │ 0 │
├──────────┼────────┼─────────┤
│ case_1 │ 1 │ 2 │
├──────────┼────────┼─────────┤
│ case_2 │ 2 │ 4 │
├──────────┼────────┼─────────┤
│ case_3 │ 3 │ 6 │
├──────────┼────────┼─────────┤
│ case_4 │ 4 │ 8 │
├──────────┼────────┼─────────┤
│ Averages │ │ │
└──────────┴────────┴─────────┘
"""
- 我们在此省略了持续时间,只是为了保持打印输出在每次运行时不变。
- 我们在此省略了持续时间,只是为了保持打印输出在每次运行时不变。
(这个例子是完整的,可以“按原样”运行)
OpenTelemetry 集成
Pydantic Evals 与 OpenTelemetry 集成以进行追踪。
EvaluatorContext 包含一个名为 span_tree 的属性,该属性返回一个 SpanTree。SpanTree 提供了一种查询和分析函数执行期间生成的 span 的方法。这提供了一种在评估期间访问检测结果的方法。
注意
如果您只是想编写单元测试来确保在调用评估任务时会产生特定的 span,通常最好直接使用 logfire.testing.capfire 装置 (fixture)。
这主要有两种用途。
import asyncio
from typing import Any
import logfire
from pydantic_evals import Case, Dataset
from pydantic_evals.evaluators import Evaluator
from pydantic_evals.evaluators.context import EvaluatorContext
from pydantic_evals.otel.span_tree import SpanQuery
logfire.configure( # ensure that an OpenTelemetry tracer is configured
send_to_logfire='if-token-present'
)
class SpanTracingEvaluator(Evaluator[str, str]):
"""Evaluator that analyzes the span tree generated during function execution."""
def evaluate(self, ctx: EvaluatorContext[str, str]) -> dict[str, Any]:
# Get the span tree from the context
span_tree = ctx.span_tree
if span_tree is None:
return {'has_spans': False, 'performance_score': 0.0}
# Find all spans with "processing" in the name
processing_spans = span_tree.find(lambda node: 'processing' in node.name)
# Calculate total processing time
total_processing_time = sum(
(span.duration.total_seconds() for span in processing_spans), 0.0
)
# Check for error spans
error_query: SpanQuery = {'name_contains': 'error'}
has_errors = span_tree.any(error_query)
# Calculate a performance score (lower is better)
performance_score = 1.0 if total_processing_time < 1.0 else 0.5
return {
'has_spans': True,
'has_errors': has_errors,
'performance_score': 0 if has_errors else performance_score,
}
async def process_text(text: str) -> str:
"""Function that processes text with OpenTelemetry instrumentation."""
with logfire.span('process_text'):
# Simulate initial processing
with logfire.span('text_processing'):
await asyncio.sleep(0.1)
processed = text.strip().lower()
# Simulate additional processing
with logfire.span('additional_processing'):
if 'error' in processed:
with logfire.span('error_handling'):
logfire.error(f'Error detected in text: {text}')
return f'Error processing: {text}'
await asyncio.sleep(0.2)
processed = processed.replace(' ', '_')
return f'Processed: {processed}'
# Create test cases
dataset = Dataset(
cases=[
Case(
name='normal_text',
inputs='Hello World',
expected_output='Processed: hello_world',
),
Case(
name='text_with_error',
inputs='Contains error marker',
expected_output='Error processing: Contains error marker',
),
],
evaluators=[SpanTracingEvaluator()],
)
# Run evaluation - spans are automatically captured since logfire is configured
report = dataset.evaluate_sync(process_text)
# Print the report
report.print(include_input=True, include_output=True, include_durations=False) # (1)!
"""
Evaluation Summary: process_text
┏━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┓
┃ Case ID ┃ Inputs ┃ Outputs ┃ Scores ┃ Assertions ┃
┡━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━┩
│ normal_text │ Hello World │ Processed: hello_world │ performance_score: 1.00 │ ✔✗ │
├─────────────────┼───────────────────────┼─────────────────────────────────────────┼──────────────────────────┼────────────┤
│ text_with_error │ Contains error marker │ Error processing: Contains error marker │ performance_score: 0 │ ✔✔ │
├─────────────────┼───────────────────────┼─────────────────────────────────────────┼──────────────────────────┼────────────┤
│ Averages │ │ │ performance_score: 0.500 │ 75.0% ✔ │
└─────────────────┴───────────────────────┴─────────────────────────────────────────┴──────────────────────────┴────────────┘
"""
- 我们在此省略了持续时间,只是为了保持打印输出在每次运行时不变。
(这个例子是完整的,可以“按原样”运行)
生成测试数据集
Pydantic Evals 允许您使用 generate_dataset 通过大语言模型生成测试数据集。
数据集可以生成为 JSON 或 YAML 格式,在这两种情况下,都会在数据集旁边生成一个 JSON schema 文件,并在数据集中引用它,因此您应该可以在编辑器中获得类型检查和自动补全功能。
from __future__ import annotations
from pathlib import Path
from pydantic import BaseModel, Field
from pydantic_evals import Dataset
from pydantic_evals.generation import generate_dataset
class QuestionInputs(BaseModel, use_attribute_docstrings=True): # (1)!
"""Model for question inputs."""
question: str
"""A question to answer"""
context: str | None = None
"""Optional context for the question"""
class AnswerOutput(BaseModel, use_attribute_docstrings=True): # (2)!
"""Model for expected answer outputs."""
answer: str
"""The answer to the question"""
confidence: float = Field(ge=0, le=1)
"""Confidence level (0-1)"""
class MetadataType(BaseModel, use_attribute_docstrings=True): # (3)!
"""Metadata model for test cases."""
difficulty: str
"""Difficulty level (easy, medium, hard)"""
category: str
"""Question category"""
async def main():
dataset = await generate_dataset( # (4)!
dataset_type=Dataset[QuestionInputs, AnswerOutput, MetadataType],
n_examples=2,
extra_instructions="""
Generate question-answer pairs about world capitals and landmarks.
Make sure to include both easy and challenging questions.
""",
)
output_file = Path('questions_cases.yaml')
dataset.to_file(output_file) # (5)!
print(output_file.read_text())
"""
# yaml-language-server: $schema=questions_cases_schema.json
cases:
- name: Easy Capital Question
inputs:
question: What is the capital of France?
metadata:
difficulty: easy
category: Geography
expected_output:
answer: Paris
confidence: 0.95
evaluators:
- EqualsExpected
- name: Challenging Landmark Question
inputs:
question: Which world-famous landmark is located on the banks of the Seine River?
metadata:
difficulty: hard
category: Landmarks
expected_output:
answer: Eiffel Tower
confidence: 0.9
evaluators:
- EqualsExpected
"""
- 定义任务输入的 schema。
- 定义任务预期输出的 schema。
- 定义测试用例元数据的 schema。
- 调用
generate_dataset来创建一个包含 2 个符合 schema 的测试用例的Dataset。 - 将数据集保存到 YAML 文件,这也会将
questions_cases.yaml的 JSON schema 写入questions_cases_schema.json,以便于编辑。这个神奇的yaml-language-server注释至少被 vscode、jetbrains/pycharm 支持(更多细节请见这里)。
(此示例是完整的,可以“按原样”运行 —— 您需要添加 asyncio.run(main(answer)) 来运行 main)
您也可以将数据集写为 JSON 文件
from pathlib import Path
from pydantic_evals import Dataset
from pydantic_evals.generation import generate_dataset
from generate_dataset_example import AnswerOutput, MetadataType, QuestionInputs
async def main():
dataset = await generate_dataset( # (1)!
dataset_type=Dataset[QuestionInputs, AnswerOutput, MetadataType],
n_examples=2,
extra_instructions="""
Generate question-answer pairs about world capitals and landmarks.
Make sure to include both easy and challenging questions.
""",
)
output_file = Path('questions_cases.json')
dataset.to_file(output_file) # (2)!
print(output_file.read_text())
"""
{
"$schema": "questions_cases_schema.json",
"cases": [
{
"name": "Easy Capital Question",
"inputs": {
"question": "What is the capital of France?"
},
"metadata": {
"difficulty": "easy",
"category": "Geography"
},
"expected_output": {
"answer": "Paris",
"confidence": 0.95
},
"evaluators": [
"EqualsExpected"
]
},
{
"name": "Challenging Landmark Question",
"inputs": {
"question": "Which world-famous landmark is located on the banks of the Seine River?"
},
"metadata": {
"difficulty": "hard",
"category": "Landmarks"
},
"expected_output": {
"answer": "Eiffel Tower",
"confidence": 0.9
},
"evaluators": [
"EqualsExpected"
]
}
]
}
"""
- 完全按照上述方式生成
Dataset。 - 将数据集保存到 JSON 文件,这也会将
questions_cases.json的 JSON schema 写入questions_cases_schema.json。这次$schema键被包含在 JSON 文件中,以定义供 IDE 在您编辑文件时使用的 schema,虽然没有正式的规范,但它在 vscode 和 pycharm 中都有效,并在 json-schema-org/json-schema-spec#828 中有详细讨论。
(此示例是完整的,可以“按原样”运行 —— 您需要添加 asyncio.run(main(answer)) 来运行 main)
与 Logfire 集成
Pydantic Evals 是使用 OpenTelemetry 来实现记录评估过程的追踪。这些追踪包含终端输出中所有信息作为属性,但也包括评估任务函数执行的完整追踪。
您可以将这些追踪发送到任何与 OpenTelemetry 兼容的后端,包括 Pydantic Logfire。
您所需要做的就是通过 logfire.configure 配置 Logfire。
import logfire
from judge_recipes import recipe_dataset, transform_recipe
logfire.configure(
send_to_logfire='if-token-present', # (1)!
environment='development', # (2)!
service_name='evals', # (3)!
)
recipe_dataset.evaluate_sync(transform_recipe)
send_to_logfire参数控制何时将追踪发送到 Logfire。您可以将其设置为'if-token-present',仅当设置了LOGFIRE_TOKEN环境变量时才将数据发送到 Logfire。更多详细信息请参阅 Logfire 配置文档。environment参数设置追踪的环境。当运行测试或评估并将数据发送到包含生产数据的项目时,最好将其设置为'development',以便在审查生产环境数据时更容易过滤掉这些追踪。service_name参数设置追踪的服务名称。这会显示在 Logfire UI 中,以帮助您识别相关 span 的来源。
Logfire 对 Pydantic Evals 追踪进行了一些特殊集成,包括在评估根 span 上提供评估结果的表格视图(该 span 在每次调用 Dataset.evaluate 时生成)
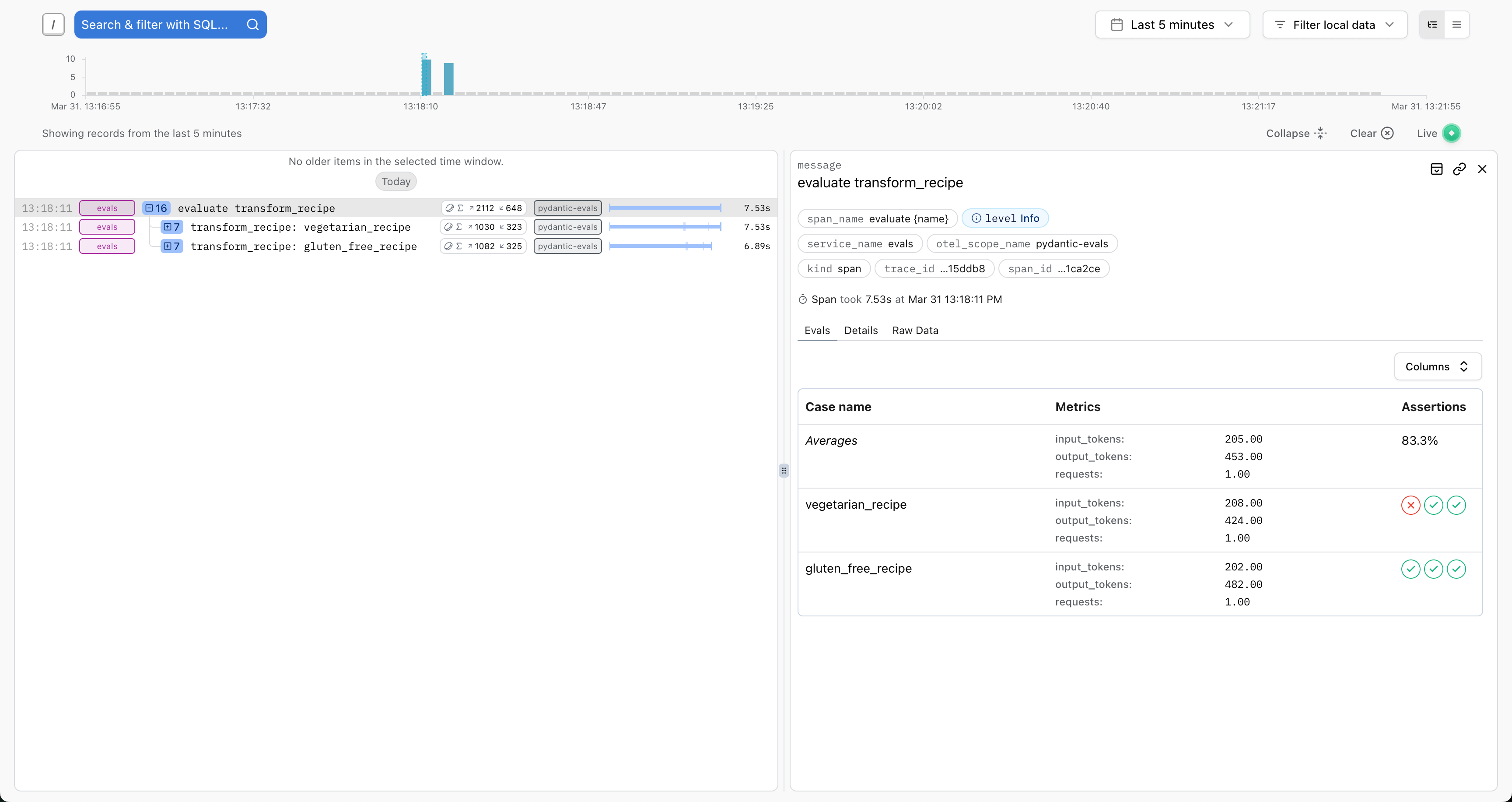
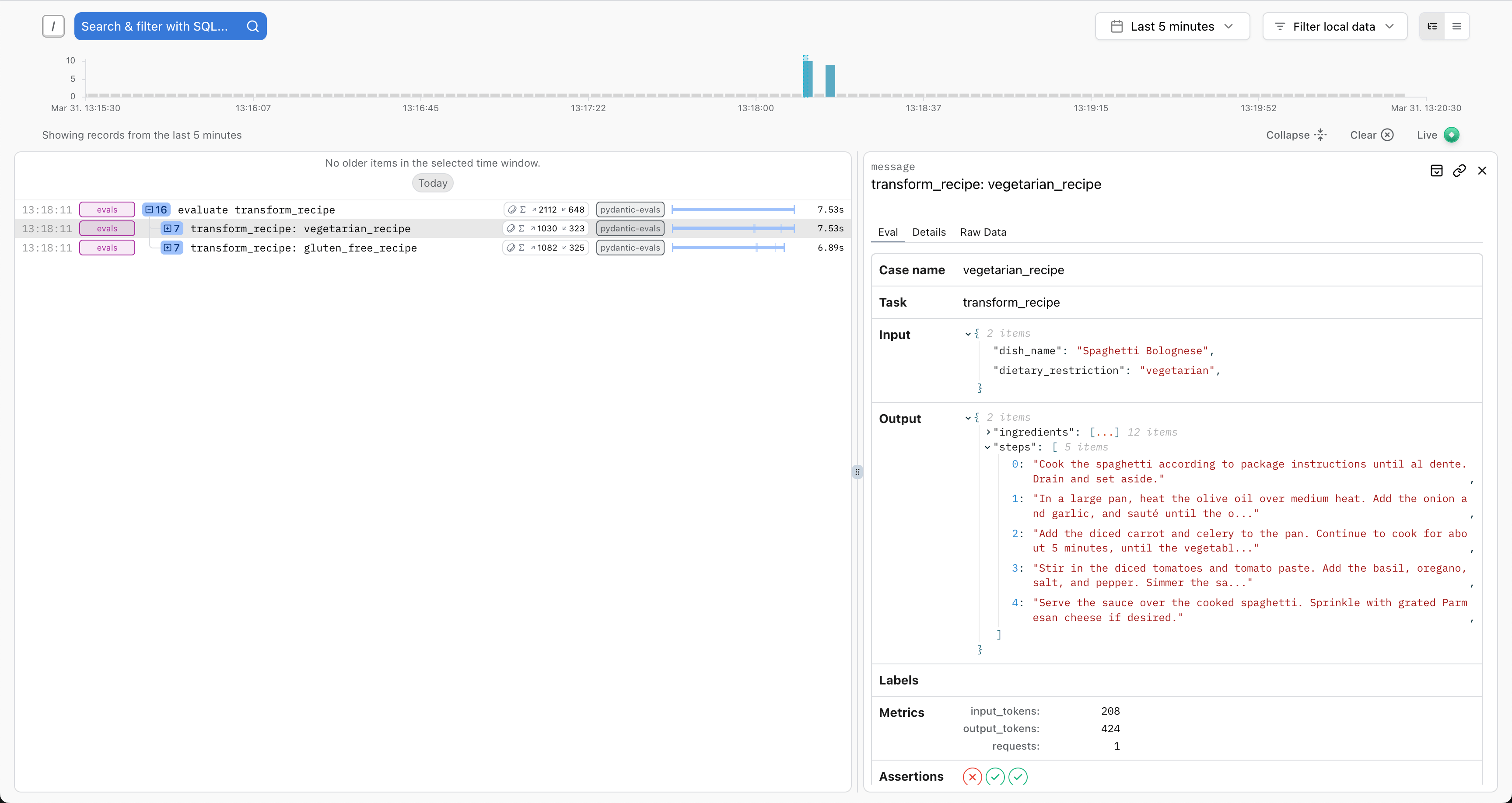
以及每个测试用例执行的输入和输出的详细视图
此外,在评估过程中生成的任何 OpenTelemetry span 都将被发送到 Logfire,让您可以可视化评估过程中调用的代码的完整执行过程。
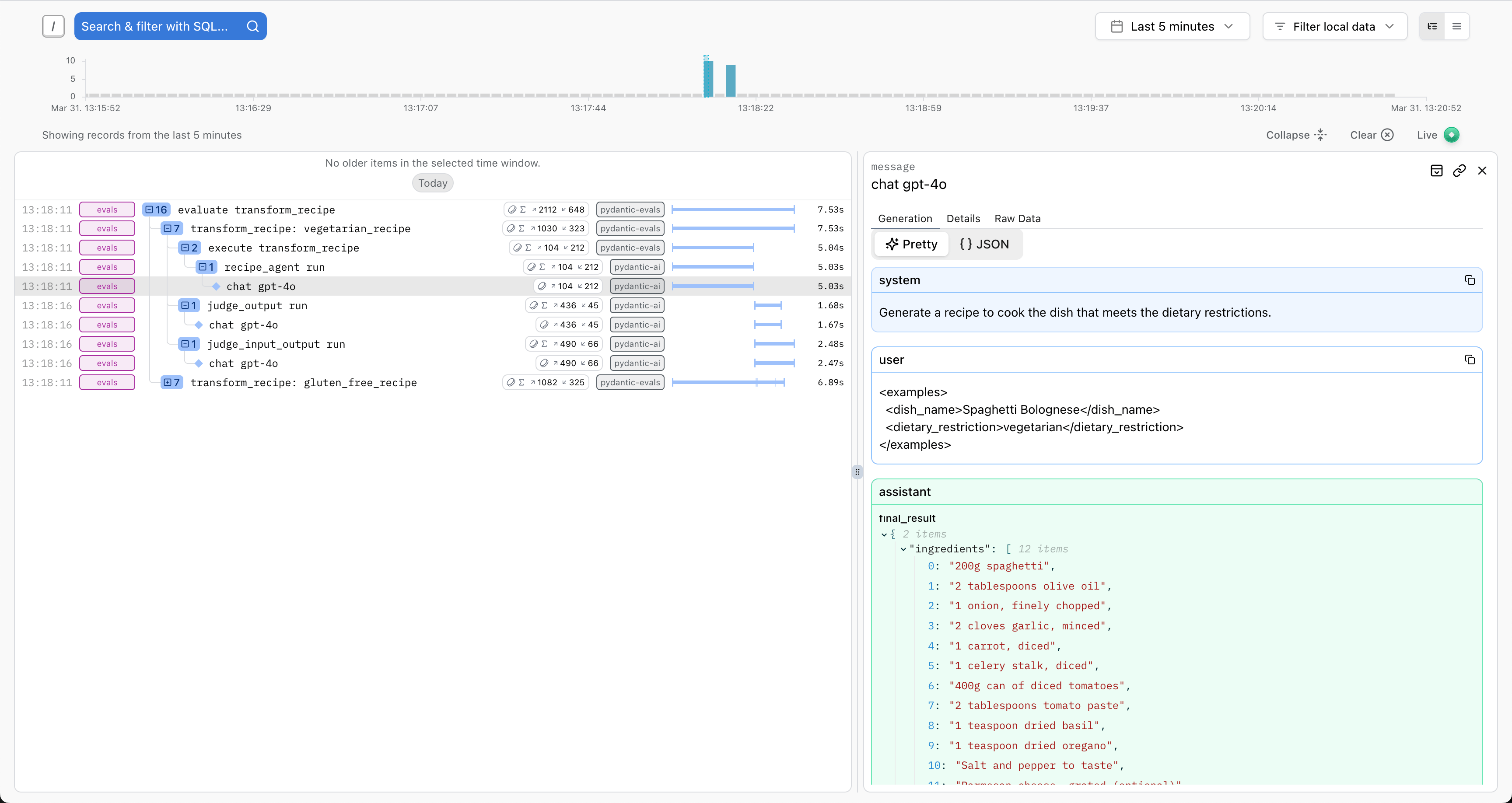
当尝试编写利用 EvaluatorContext 的 span_tree 属性的评估器时,这尤其有用,如上文的 OpenTelemetry 集成部分所述。
这使您可以编写依赖于任务函数调用期间执行了哪些代码路径信息的评估,而无需手动检测被评估的代码,只要被评估的代码已经用 OpenTelemetry 进行了充分的检测。例如,在 Pydantic AI 代理的情况下,这可以用来确保在执行特定测试用例时调用(或不调用)特定的工具。
以这种方式使用 OpenTelemetry 也意味着所有用于评估任务执行的数据都可以在代码的生产运行所产生的追踪中访问到,从而可以轻松地对生产数据执行相同的评估。